Who Runs It?
The demo shipped. The repo is green. The staging environment holds. The CI passed. The system is in production, running on a Ghost instance, serving real traffic.
Now a question nobody asked during the sell arrives at the door.
Who runs it?
The tactical version of that question is easy. Who maintains it. Who patches a CVE. Who is on call this weekend. Those answers have standard shapes. The strategic version is harder. Over the next year, as this system mutates, scales, grows new features, absorbs new clients, integrates with upstream systems, survives an outage, drifts from its original architecture, and eventually needs a successor, who holds it?
This is Step 3. Most AI content stops at Step 2 and pretends Step 3 is a training problem that happens after the real work. It is not. And the traditional answer to it is backwards.
Step one and step two
You know Step 1. AI gave it to everyone for free. Cursor. Claude Code. GPT in a notebook. A Vibe Creator session that generates a foundation in twenty minutes. Step 1 is the demo, the prototype, the screenshot, the look-at-this moment. Almost every LinkedIn post about AI is about Step 1.
Step 2 is the light-year jump. Step 2 is the running system. Real Git workflow. Real pull requests reviewed by humans. Real Jira decomposition. Real deployments to real infrastructure. Real tests catching real regressions. Real observability catching the things the tests missed. The Forge booting every phase. Fleet standing up Ghost instances. Most AI coverage in the industry stops celebrating somewhere inside Step 1 and never names Step 2.
Step 3 is the mature team. It is a gap as wide as Step 2 was, hidden behind the Step 2 victory.
The gap nobody writes about
A production system is not the end of the work. It is the start of a different kind of work. The Modern Principal who shipped it knows the shape of every file. She knows which phase of the Miracle wrote which module. She knows which cosmic emission explains which architectural decision. She can open any log and read what happened there, because she was there when it happened.
None of that transfers through a README.
When she hands the system to the next person, she hands over a working binary and a set of written instructions. The next person has to derive the shape by reading, operating, breaking, and repairing. That derivation takes months, and during those months the system is fragile in ways that are not anyone’s fault. It is a fragility of context.
Scale that across a team. A VP of Engineering who inherits a production system from a four-person build team faces an asymmetric transfer. The builders hold years of context compressed into weeks of building. The inheriting team has to unpack years of context in the weeks before the next thing has to ship. The math does not work.
The traditional answer, and why it is backwards
The industry’s standard response to Step 3 has been: train the team on cloud operations first, then hand them the system.
Train them on AWS. Train them on Kubernetes. Train them on infrastructure as code. Train them on observability stacks. Train them on incident response. Train them on SRE practices, capacity planning, cost monitoring, compliance. Six months of training. A course catalog. A certification path. Maybe a sabbatical to an external bootcamp.
Then, and only then, hand them the system and say “it’s yours now.”
This is backwards, and it fails for two reasons.
First, the training is abstract. Trainees learn AWS on a sandbox account that looks nothing like the production account they will operate. They learn Kubernetes on a cluster that has no real traffic, no real incident history, no real blast radius. The muscle memory they build during training does not map to the muscle memory they will need on day one of actually holding the system. They come out of training feeling ready and discover on the first incident that ready was a feeling, not a capability.
Second, the timeline does not work. A CTO cannot afford six months of training before the team is operational. The system is in production now. Clients are using it now. The system needs hands on it now. Every day the team is not yet ready is a day of continuity risk sitting on the Principal who built it, who cannot move to the next engagement because she cannot yet leave this one.
The training-first model is an artifact of an era when systems lived on premises and the pace of change was measured in quarters. That era is over. The system is cloud resident, its pace is measured in daily deployments, and the team has to learn to hold something that is already moving.
Backwards from solution
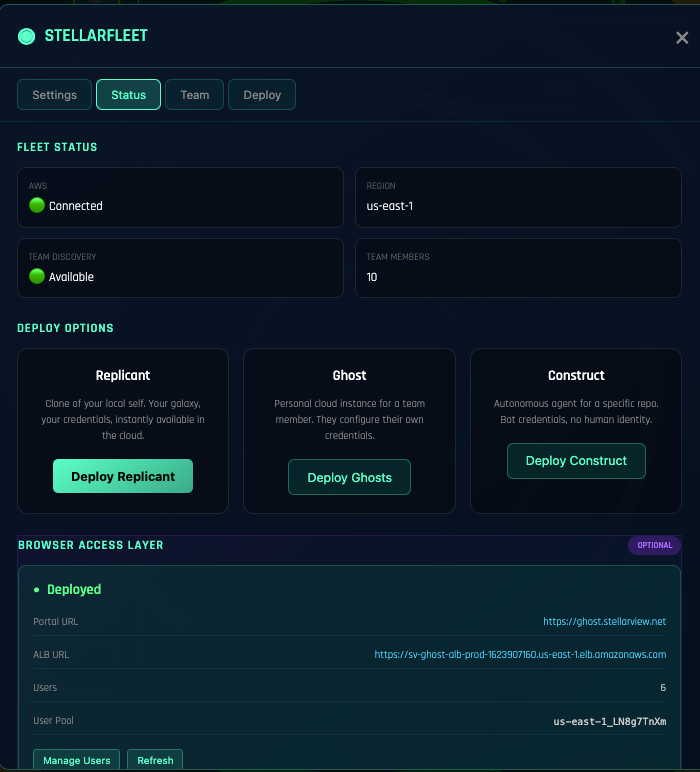
Fleet inverts the direction.
Instead of training the team forward from abstract foundations, Fleet starts with the running solution and wraps the team around it.
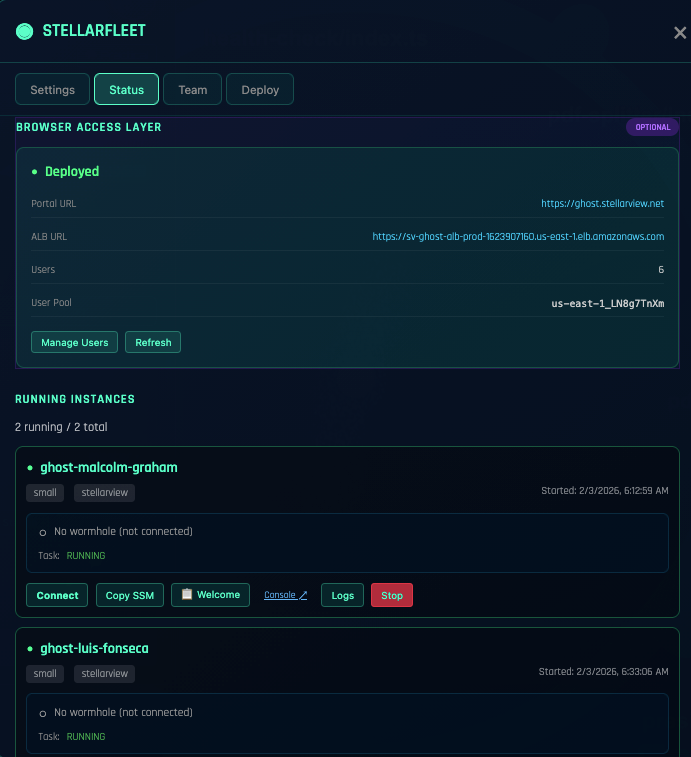
The production system is already live on a Ghost instance. The Ghost is a StellarView-managed ephemeral compute surface, observable from day one, with telemetry flowing into cosmic emissions that the team can read like a narrative. A new operator does not start by learning “what is Kubernetes.” She starts by watching what this specific Ghost is doing. She sees the traffic pattern. She sees the error rate. She sees the last deploy. She sees the last incident. She sees the Principal’s notes about why the configuration is what it is.
Access to the Ghost is through the Transporter Room, a Cognito-authenticated gateway that gives each team member scoped access to the running instance. The Transporter Room is the shop floor. It is where operators develop the instinct to read a system under load, because they are reading a system under load, not a lab reproduction.
Fleet governs the portfolio of Ghosts across all the Principal’s engagements. When the team’s competence is ready to expand, Fleet adds a second Ghost under their responsibility. Then a third. Competence compounds by operating, not by rehearsing.
This is not a training program. This is an operating environment that produces trained operators as a side effect of holding the systems they are supposed to hold.
The team forms around the system
The order of operations matters.
In the old model, the company has a team, and the team has skills, and the skills shape what the team can hold. If the team does not know AWS, the company cannot hold an AWS-native system, and hiring AWS-native talent is the prerequisite for doing anything with AWS.
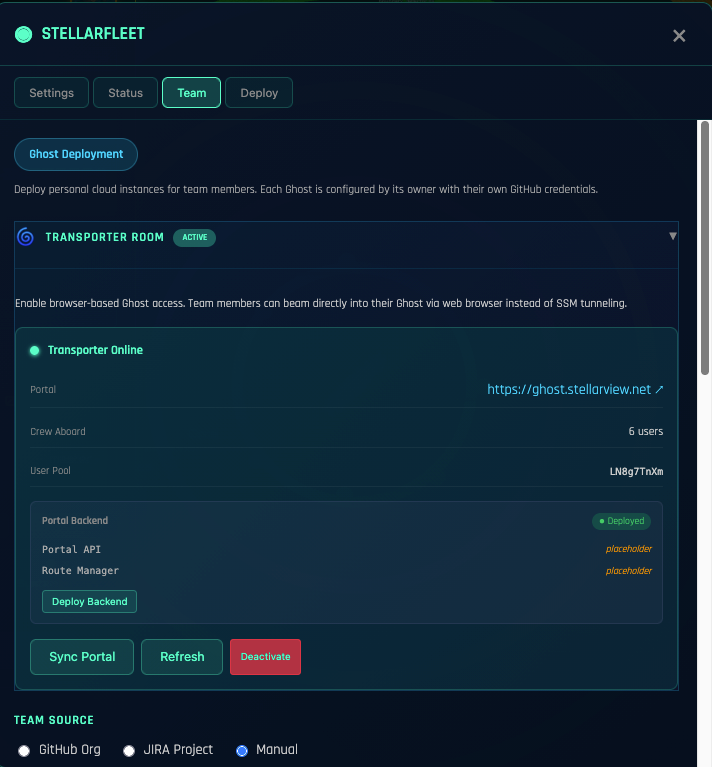
In the Fleet model, the company has a system, and Fleet provides the operating surface, and the team grows into the surface. The skills are shaped by the system, not the other way around. The team that forms around a running Ghost is an operations team for that specific Ghost’s shape. When the next system arrives with a different shape, Fleet onboards the team to that one too, and the shape-specific skill transfers what it can while Fleet holds the parts that do not transfer.
This sounds abstract. Concretely: a CTO does not need her team to know Kubernetes before she can hold a Kubernetes-native system. She needs Fleet to hold the Kubernetes parts while her team develops the system-specific operational instinct. Over time, the Kubernetes fluency accumulates as a side effect of operating actual Kubernetes-shaped systems, not as a prerequisite for doing so.
The commercial weight
A training-first Step 3 strategy is a six-month gap between shipping and holding. A backwards-from-solution Step 3 strategy is a day-one gap. The difference is not marginal.
For a consulting engagement where the Principal cannot leave until the client team can hold the system, the training-first gap is where profitability dies. Every week the Principal is still on the hook after the contract closed is a week of revenue recognized against zero hours budgeted, which is a real loss, which is why consulting firms that still operate on the training-first model are losing money on every AI engagement and telling themselves they are investing.
For an internal engineering team inheriting a platform from a departing vendor, the training-first gap is where continuity risk lives. The system keeps running because it was built to, but nobody on the new team can tell you why it was built that way, and the first time the system needs to change, the change happens by accident. Accidental changes to production systems is how outages start.
Closing the Step 3 gap is not a nice-to-have feature. It is the difference between a platform engagement that closes cleanly and one that rots because the Principal is still on call a quarter after the contract ended.
The question to ask before you build
If you are designing a new system and Step 3 is a real concern for you, the question to ask is not “who will we train to run this?” The question is:
What shape of system is my team going to form around?
That question reframes the build. It changes what you architect for: observability over elegance. What you document: operational patterns, not implementation detail. What you hire for: people who can read a system under load, not people who memorized the runtime. What you budget for: the Fleet layer that will hold the team up during the first ninety days of operation.
The Modern Principal does not ship a system and then ask who runs it. She ships a system with the answer already forming around it. Backwards from the running solution. The team grows into the shape of the thing.
That is Step 3. Most of the practice is still ahead of us, because most of the industry has not yet noticed the gap is there.